Carl Cervone
Levels of the game: the psychology of RetroPGF and how to build a better game
December 14, 2023
This post was original published on the Open Source Observer blog, availabe here
RetroPGF is a unique kind of repeated game. With each round, we are iterating on both the rules and the composition of players. These things matter a lot. To get better, we need to study whether the rules and player dynamics are having the intended effect.
This post looks at the psychology of the game during Round 3, identifies mechanics that might have caused us to deviate from our intended strategy, and suggests ways of mitigating such issues in the future.
Disclaimer: I was a voter and had a project in Round 3. I also made a lot of Lists.
Learning to outperform “spray and pray”
It is impractical to thoroughly review more than 100 projects, let alone 600+.
Here’s what Greg did:
https://twitter.com/gregthegreek/status/1732552831196876816?ref_src=twsrc%5Etfw
Spray and pray is a natural reaction to cognitive overload and limited bandwidth.
However, our focus shouldn’t be solely on creating more efficient tools for spraying. A new feature like a CSV upload button would make the work go faster, but it still encourages us to spray.
What we actually need are better ways of designing, iterating, and submitting complete voting strategies.
A voting strategy is a way of testing a hypothesis that funding certain types of projects (X) in the past will result in more desirable outcomes (Y) in the future. We want to use our voting power to incentivize agents to work in areas they know will be rewarded.
There are at least four components to designing a voting strategy:
-
Impact Vector: Identifying the type of impact you want to amplify over time.
-
Distribution Curve: Determining how flat or skewed the eventual distribution of tokens to projects should be.
-
Eligibility Criteria: Establishing parameters to determine which projects qualify.
-
Award Function: Creating a formula or rubric to equate impact with profit.
Currently, badgeholders don’t have much scaffolding to build voting strategies. It’s unrealistic to expect badgeholders to do this work from scratch.
The initial step of defining the impact vector is often the most challenging. To assist in this, we should provide badgeholders with comparative choices to help them identify their preferences. Examples could include:
-
Focusing on attracting new developers versus enhancing the experience for existing ones.
-
Prioritizing virtual community-building efforts versus more in-person events.
-
Concentrating on impacts specific to the Superchain as opposed to impacts affecting the entirety of Ethereum.
Performing these kinds of assessments at the beginning or even during the planning stage of the next RetroPGF round would not only aid badgeholders in formulating their voting strategies but also ensure alignment with the broader intents of the Citizen’s House.
Giving domain experts a platform
Popularity and name recognition are seldom reliable measures of true impact.
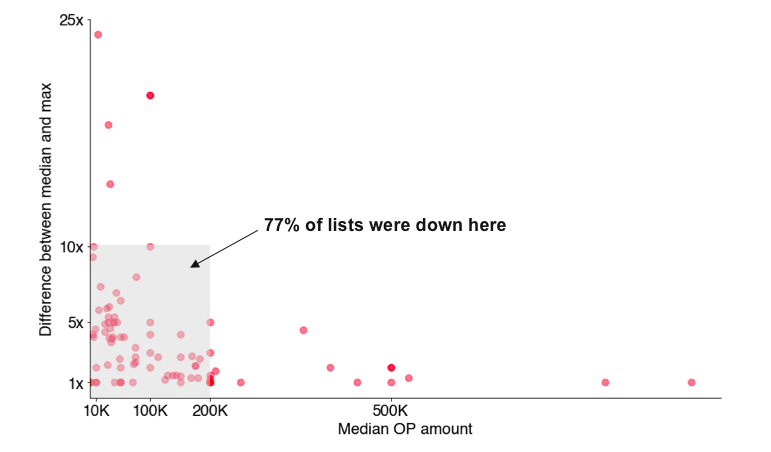
When we look for a restaurant on Google or Yelp, we usually don’t want the one with the most reviews. Instead we look for restaurants with a high proportion of detailed five-star ratings. In RetroPGF, the List feature aimed to highlight impactful projects for voters to add to their ballots. However, most Lists showed a conservative distribution of tokens, with little variance between top and median recommendations. This is the equivalent of going onto Yelp and only finding average three-star reviews.
 </img>
</img>
Katie Garcia made a similar point on the forum about low-quality Lists being a drag on the process.
To get stronger opinions, we need to encourage experts to step up and make Lists.
As with any independent review, the expertise, affiliation, and reputation of the List maker is just as important as the List itself. Voters should be able to quickly discern the credibility of a List creator.
While “liking” a List provided some measure of quality, it was unclear how many badgeholders actively utilized this feature. Another problem was that the likes only accrued to the List, not the List maker. Because we could not edit a List, a V2 of the same List started off at zero likes.
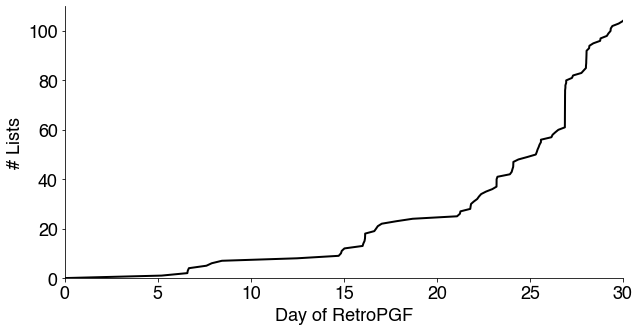
Finally, most Lists were generated towards the end of the round, giving the creator very little time to develop a reputation and voters little time to determine if it was useful to their voting strategy.
 </img>
</img>
Experts should be encouraged to play a larger role in reviewing projects and crafting Lists within their areas of expertise. This includes both helping categorize projects effectively at the start of the round and offering ratings across the full quality spectrum.
Experts should be evaluating projects on multiple impact dimensions, not just issuing absolute scores. For example, a List focused on user growth will have different project rankings than one centered on security. It’s common to see product reviews that consider multiple features and then weight those features to arrive at a final score.
Experts need to be placed in a position where they don’t feel pressure to conform to social pressure. The same is true for whisteblowers. It’s hard to combat the herd mentality that forms in large groups with only certain types of people speaking.
In academia, there’s an awareness that today’s reviewer could become tomorrow’s reviewee. To address this awkwardness, academics use blind reviews. The identities of the reviewers are kept hidden from the participants. A double-blind review extends this anonymity further, concealing the identities of both parties involved. For RetroPGF, implementing blind reviews could mean adopting pseudonymous reviews and List creation. A double-blind system, while more complex, could be realized through the use of standardized impact reports. Another possibility is to organize reviewers so that they are grouped in a domain where there’s no potential for conflict of interest.
While expert-driven systems can be criticized as technocratic, Optimism can address these concerns by promoting transparent and replicable project metrics, supporting its community of grassroots analysts (e.g., Numba Nerds), and requiring experts to publish their evaluation criteria along with their recommendations.
Using data to improve decision-making
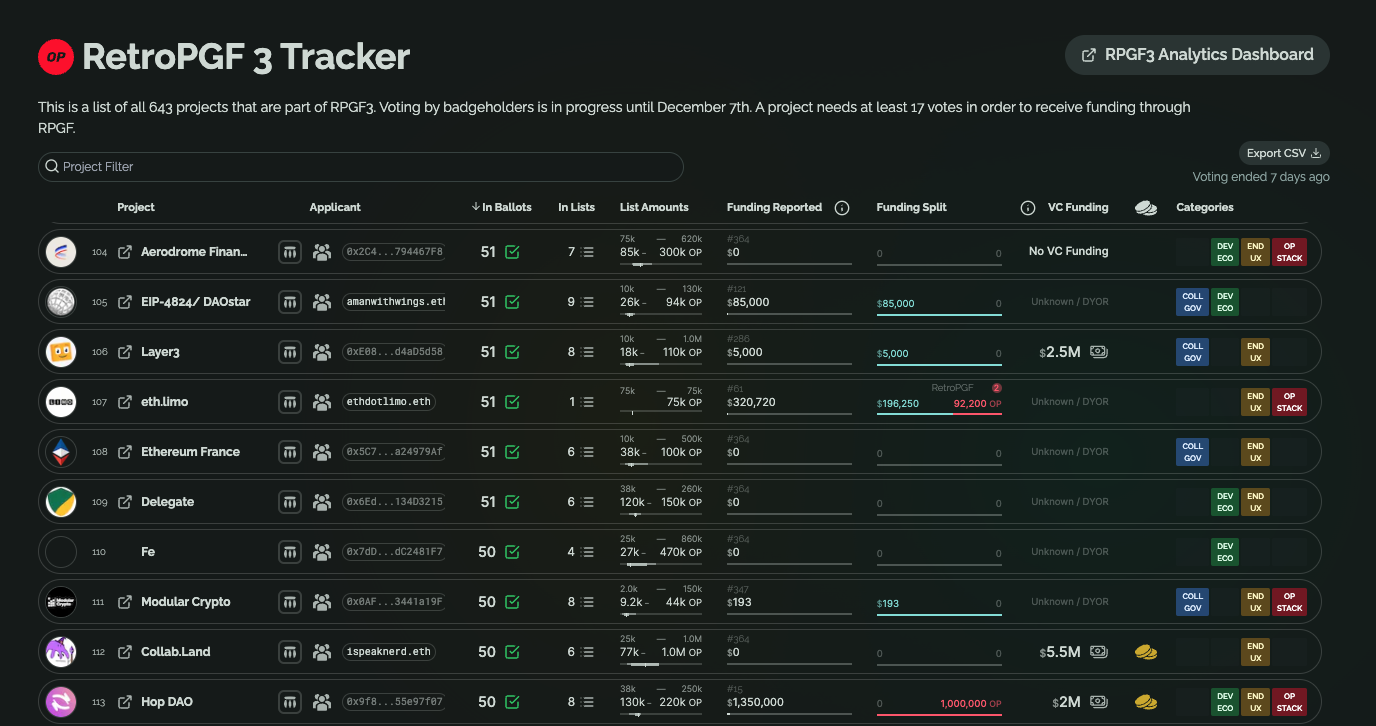
The site growthepie played a vital role during the voting period by providing easily accessible and filterable data about projects, such as their presence on ballots/Lists and funding history. This addition, as well as other sites like RetroList, RetroPGFHub, and hopefully our own, Open Source Observer, gave voters more data points to assist with voting.
 </img>
</img>
Across the board, voters demonstrated a strong preference for having data in the loop when voting or coming up with their strategies.
As we saw during the round, the best time to request relevant data from projects is during the application phase. However, while projects submitted numerous links to their contributions and impact metrics, the numbers were all self-reported. The nature of self-reported metrics raises concerns about accuracy and data entry errors.
Moreover, the data was cumbersome to analyze without individually examining each project’s page. There was no way of comparing similar metrics about similar projects unless you cleaned the data and did the analysis on your own.
Although some badgeholders are committed to conducting their own research, the process of gathering and synthesizing information from various public sources is time-consuming. Streamlining access to comparable impact metrics would significantly aid in the efficient filtering and ranking of projects.
A better approach than self-reporting would be for projects to directly link all relevant work artifacts, such as GitHub repositories, in their applications. This would enable comparable impact metrics to be surfaced automatically from any source where data integration is possible. After linking their artifacts, perhaps projects could get the option to include different “impact widgets” on their profile to highlight the ones that are most relevant to assessing their project.
Data doesn’t tell the whole story. And not all forms of impact are well-suited to some kind of metrics integration. Those are places where tools for making relative comparisons can really shine.
Encouraging relative comparisons over absolute allocations
Another thing we learned from all our “three-star Lists” is how difficult it is to quantify impact in absolute terms. It’s much easier to assess impact in relative terms.
This is what algorithms like pairwise matching are good for. I experimented with the Pairwise app during RetroPGF, but found it difficult given the sheer number of projects and the nature of comparing two projects objectively. A more targeted approach, asking voters to make a more specific comparison, e.g, “do you think Project A or B had more impact on X”, could be more effective.
Another twist on pairwise is to rate a project’s recent impact against its past performance. This is reminiscent of the traditional budgeting process of setting this year’s budget in relation to last year’s, only now we’re doing it retroactively and from the vantage point of a community not a CFO.
There’s also setwise comparison, where we analyze how often a project appears in different sets. The most impactful governance project might be the one that appears on a large number of lists independently. Quadratic voting harnesses the power of setwise comparisons. However, effort needs to be taken to prevent sets that are purely based on popularity or name recognition.
In the final 48 hours of the vote, we saw a good example of setwise comparison. Badgeholders made a push to identify borderline projects that needed just a few more votes to meet the quorum.
https://twitter.com/the_ethernaut/status/1732164445197967576?ref_src=twsrc%5Etfw
When looking at a borderline project, the voter just had to make one decision: do I want this project to be in the above or below quorum set.
Yet, as Andrew Coathup noted, this well-intentioned approach might have inadvertently skewed our true preferences:
Badgeholders who “like” a project rather than “love” an impactful project are likely to bring down a project’s median.
In retrospect, it would have been more effective to focus on removing bad apples at the start rather than searching for good apples at the end.
Understanding how game mechanics affect distributions
The experience above is just one of numerous examples of how the rules of the game will affect the distribution.
If you give the same voters the same projects, but vary the rules, you’ll almost certainly get different results. It’s not clear which type of curve the Collective wants to design for.
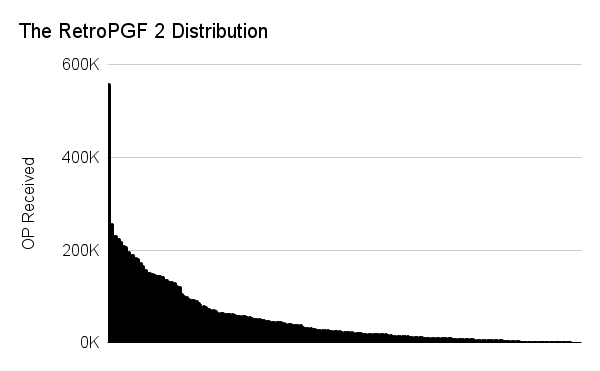
The results from RetroPGF 2 were pretty exponential. The top project received 20 times more tokens than the median project. Voters didn’t seem upset about this outcome. A comparison with RetroPGF 3’s outcomes and the community’s reaction will be insightful, and may surface if there are strong preferences for one form of distribution pattern over another.
 </img>
</img>
Exponential distributions are generally better for tackling complex problems with low odds of success. They channel more resources into fewer, higher impact projects. Conversely, flatter distributions encourage a broader range of teams to pursue more achievable objectives. Both have their place.
The other big distribution question is how meritocratic it is. A meritocratic system would consistently elevate the highest-impact projects to the top of the token distribution, independent of voter identity or the number of competing projects. If the distribution has a long tail, then there will always be a high degree of randomness and variation in it.
The distribution patterns that emerge through repeated games will inevitably affect the mindset of projects and builders who continue to participate. If the model feels like a black box, then the best players will lose the motivation to keep playing.
Given the significance of these outcomes, it’s crucial to simulate and understand the implications of different rule sets before implementing them in upcoming rounds.
Navigating questions around prior funding sources
There was a lot of debate within the badgeholder group and on Twitter about how a project’s funding history and business model should affect its allocation. Many community members including but not limited to Lefteris had strong views.
https://twitter.com/LefterisJP/status/1730689350659129804?ref_src=twsrc%5Etfw
Like most political issues, once you dig deeper, you realize there’s a lot of nuance. People’s opinions fall along a spectrum. We can get a sense for where the community is on this spectrum by giving them hypothetical comparisons like the following:
-
Should a ten-person team receive more funding than a two-person team?
-
Does a full-time project deserve more support than a part-time effort or side hustle?
-
Should a team in a higher GDP region receive more funding than one in a lower GDP area?
-
Does the absence of venture capital funding merit more allocation compared to projects with such backing?
-
Should teams with limited financial resources be prioritized over those with substantial funds?
-
Does a team generating no revenue deserve more support than one with recurring revenue?
-
Should projects offering solely public goods receive more funding than those mixing public and non-public goods?
-
Do teams without prior grants merit more support than those frequently receiving grants?
-
Should a project never funded by Optimism be prioritized over one that has received multiple grants?
-
Should a protocol on Optimism with no fees receive more funding than one with fees?
Currently, guidelines state that voters should only consider points 9 and 10. Yet many voters struggle to disregard the other aspects.
To prevent these financial factors from skewing voting, the Collective might need to reevaluate its approach. This type of challenge is another reason why academics use double-blind reviews: the reviewer is forced to only consider the quality of the paper, not how deserving is the team behind the paper.
A potential solution for RetroPGF could involve segregating projects and funding pools. This could alleviate some of the pressure on voters to choose between projects with vastly different funding requirements and access to capital.
While this issue is important, it’s regrettable that the focus on reviewing a project’s funding sources may have gotten in the way of reviewing its actual impact.
Playing the game better
I’ll end with a recap of my recommendations for how Optimism might get better at playing the game both next round and over the long run.
Our primary goal should be to surpass the ‘spray and pray’ approach. To achieve this, we need to dig deeper into understanding voters’ value preferences and let this knowledge shape the game’s dynamics. This encompasses everything from the types of impact voters care about to the financial aspects they consider relevant in reviewing projects. We can start by gathering insights from surveys, forum discussions, and post-round retrospectives. However, acquiring more substantial data before and during the round is essential. This data will be instrumental in differentiating between UI/UX challenges (like updating ballots and lists) and game mechanics issues (such as whether voters should review every project). Critically, we should monitor and simulate how closely the actual outcomes align with voters’ expectations regarding funding allocation and distribution patterns.
Improving project comparison methods, reducing bias, and encouraging independent thinking are crucial. We must avoid turning this into a popularity contest by empowering domain experts to have greater influence and build their reputation. Since quantifying absolute impact is challenging, we should focus on better understanding relative impacts and making more effective comparisons. To combat herd mentality and the pressure to conform, exploring blind review mechanisms could be beneficial. Having objective data readily available will assist in making informed decisions and identifying both the strongest and weakest projects.
The voting experience should be optimized to support voters in testing and implementing a well-defined strategy. At the end of each round, voters should have a clear understanding of the process and feel confident about their participation and choices. Speaking from personal experience, I am uncertain about my own effectiveness in the game. Despite investing time in identifying worthy projects and avoiding less desirable ones, I’m unsure if I maximized the potential of my top picks. There’s a need for a system that helps voters articulate and evaluate their strategies clearly, as this is key to getting better at a repeated game.
This work won’t be easy. But the upside is huge.